OLAP、OLTP-Vergleich
Dieser Artikel wird von https übertragen://www.cnblogs.com/hhandbibi/p/7118740.html
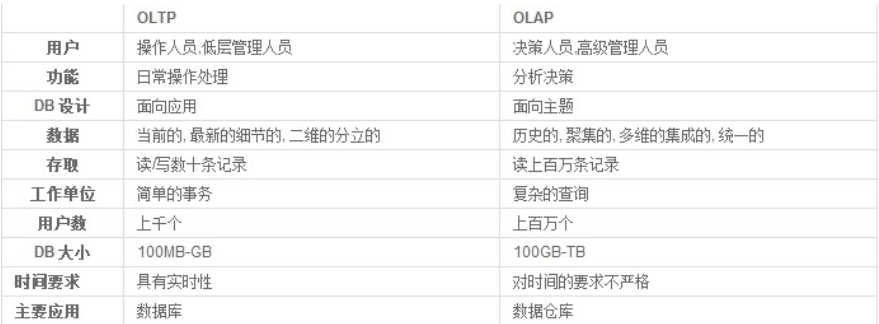
OLTP与OLAP的介绍
数据处理大致可以分成两大类:OLTP (Online-Transaktionsverarbeitung)、
OLAP (Online-Analyseverarbeitung)。OLTP是传统的关系型数据库的
主要应用,Hauptsächlich einfach、Tägliche Angelegenheiten,z.B. Bankgeschäfte。OLAP是数据仓库系统的
主要应用,Unterstützung komplexer Analysevorgänge,Fokus auf Entscheidungsunterstützung,Und bieten intuitive und leicht verständliche Abfrageergebnisse。
OLTP 系统强调数据库内存效率,Betonen Sie die Befehlsrate verschiedener Speicherindikatoren,Betonung auf Bindevariablen,Betonen Sie gleichzeitige Vorgänge;
OLAP 系统则强调数据分析,Betonen Sie den SQL-Ausführungsmarkt,Betonen Sie die Festplatten-E/A,Betonen Sie Partitionen usw.。
OLTP,Auch Online-Transaktionsverarbeitung genannt (Online Transaction Processing),Stellt ein sehr transaktionales System dar,
Generell hochverfügbare Online-Systeme,Konzentrieren Sie sich auf kleine Transaktionen und kleine Abfragen,Bei der Bewertung seines Systems,一般看其每秒
执行的Transaction以及Execute SQL的数量。In einem solchen System,单个数据库每秒处理的Transaction
往往超过几百个,Oder ein paar Tausend,Das Ausführungsvolumen von Select-Anweisungen beträgt Tausende oder sogar Zehntausende pro Sekunde。典型的OLTP系统有
电子商务系统、Bank、Wertpapiere usw.,Wie die Unternehmensdatenbank von eBay in den USA,Es ist eine sehr typische OLTP-Datenbank。
Der wahrscheinlichste Engpass in OLTP-Systemen sind die CPU- und Festplatten-Subsysteme。
(1) CPU-Engpässe manifestieren sich häufig in der Gesamtmenge der logischen Lesevorgänge und Rechenfunktionen oder -prozesse,逻辑读总量等于单个语句的
逻辑读乘以执行次数,Wenn die Ausführungsgeschwindigkeit einer einzelnen Anweisung hoch ist,Aber die Zahl der Hinrichtungen ist sehr groß,So,也可能会
导致很大的逻辑读总量。Die Methode des Entwurfs und der Optimierung besteht darin, das logische Lesen eines einzelnen Satzes zu reduzieren,Oder um sie zu reduzieren
执行次数。Außerdem,一些计算型的函数,如自定义函数、decode等的频繁使用,也会消耗大量的CPU
时间,造成系统的负载升高,正确的设计方法或者是优化方法,需要尽量避免计算过程,如保存计算
结果到统计表就是一个好的方法。
(2)磁盘子系统在OLTP环境中,它的承载能力一般取决于它的IOPS处理能力. 因为在OLTP环境中,
磁盘物理读一般都是db file sequential read,也就是单块读,但是这个读的次数非常频繁。如果频繁
到磁盘子系统都不能承载其IOPS的时候,就会出现大的性能问题。
OLTP比较常用的设计与优化方式为Cache技术与B-tree索引技术,Cache决定了很多语句不需要从
磁盘子系统获得数据,und so,Web cache与Oracle data buffer对OLTP系统是很重要的。Außerdem,在索引
使用方面,语句越简单越好,这样执行计划也稳定,而且一定要使用绑定变量,减少语句解析,尽量
减少表关联,尽量减少分布式事务,基本不使用分区技术、MV技术、并行技术及位图索引。因为
并发量很高,批量更新时要分批快速提交,以避免阻塞的发生。
OLTP 系统是一个数据块变化非常频繁,SQL 语句提交非常频繁的系统。 对于数据块来说,应尽
可能让数据块保存在内存当中,对于SQL来说,尽可能使用变量绑定技术来达到SQL重用,减少
物理I/O 和重复的SQL 解析,从而极大的改善数据库的性能。
这里影响性能除了绑定变量,还有可能是热快(hot block)。 当一个块被多个用户同时读取时,
Oracle 为了维护数据的一致性,需要使用Latch来串行化用户的操作。当一个用户获得了latch后,
其他用户就只能等待,获取这个数据块的用户越多,等待就越明显。 这就是热快的问题。 这种热快
可能是数据块,也可能是回滚端块。 对于数据块来讲,通常是数据库的数据分布不均匀导致,im Falle
是索引的数据块,可以考虑创建反向索引来达到重新分布数据的目的,对于回滚段数据块,可以
适当多增加几个回滚段来避免这种争用。
OLAP,也叫联机分析处理(Online Analytical Processing)系统,有的时候也叫DSS
决策支持系统,就是我们说的数据仓库。In einem solchen System,语句的执行量不是考核标准,因为一条
语句的执行时间可能会非常长,读取的数据也非常多。und so,In einem solchen System,考核的标准往往是
磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。
磁盘子系统的吞吐量则往往取决于磁盘的个数,这个时候,Cache基本是没有效果的,数据库的
读写类型基本上是db file scattered read与direct path read/write。应尽量采用个数比较多的磁盘
以及比较大的带宽,如4Gb的光纤接口。
在OLAP系统中,常使用分区技术、并行技术。
分区技术在OLAP系统中的重要性主要体现在数据库管理上,比如数据库加载,可以通过分区
交换的方式实现,备份可以通过备份分区表空间实现,删除数据可以通过分区进行删除,至于
分区在性能上的影响,它可以使得一些大表的扫描变得很快(只扫描单个分区)。Außerdem,如果分区
结合并行的话,也可以使得整个表的扫描会变得很快。总之,分区主要的功能是管理上的方便性,
它并不能绝对保证查询性能的提高,有时候分区会带来性能上的提高,有时候会降低。
并行技术除了与分区技术结合外,在Oracle 10g中,与RAC结合实现多节点的同时扫描,效果也
非常不错,可把一个任务,如select的全表扫描,平均地分派到多个RAC的节点上去。
在OLAP系统中,不需要使用绑定(BIND)变量,因为整个系统的执行量很小,分析时间对于
执行时间来说,可以忽略,而且可避免出现错误的执行计划。但是OLAP中可以大量使用位图索引,
物化视图,对于大的事务,尽量寻求速度上的优化,没有必要像OLTP要求快速提交,甚至要刻意
减慢执行的速度。
绑定变量真正的用途是在OLTP系统中,这个系统通常有这样的特点,用户并发数很大,用户的
请求十分密集,并且这些请求的SQL 大多数是可以重复使用的。
对于OLAP系统来说,绝大多数时候数据库上运行着的是报表作业,执行基本上是聚合类的SQL
操作,比如group by,这时候,把优化器模式设置为all_rows是恰当的。 而对于一些分页操作
比较多的网站类数据库,设置为first_rows会更好一些。 但有时候对于OLAP 系统,我们又有
分页的情况下,我们可以考虑在每条SQL 中用hint。 Sowie:
Select a.* from table a;
分开设计与优化
在设计上要特别注意,如在高可用的OLTP环境中,不要盲目地把OLAP的技术拿过来用。
如分区技术,假设不是大范围地使用分区关键字,而采用其它的字段作为where条件,So,
如果是本地索引,将不得不扫描多个索引,而性能变得更为低下。如果是全局索引,又失去
分区的意义。
并行技术也是如此,一般在完成大型任务时才使用,如在实际生活中,翻译一本书,可以先
安排多个人,每个人翻译不同的章节,这样可以提高翻译速度。如果只是翻译一页书,也去
分配不同的人翻译不同的行,再组合起来,就没必要了,因为在分配工作的时间里,一个人
或许早就翻译完了。
位图索引也是一样,如果用在OLTP环境中,很容易造成阻塞与死锁。但是,在OLAP环境中,
可能会因为其特有的特性,提高OLAP的查询速度。MV也是基本一样,包括触发器等,在DML
、频繁的OLTP系统上,很容易成为瓶颈,甚至是Library Cache等待,而在OLAP环境上,dann
可能会因为使用恰当而提高查询速度。
对于OLAP系统,在内存上可优化的余地很小,增加CPU 处理速度和磁盘I/O 速度是最直接
的提高数据库性能的方法,当然这也意味着系统成本的增加。
比如我们要对几亿条或者几十亿条数据进行聚合处理,这种海量的数据,全部放在内存中
操作是很难的,同时也没有必要,因为这些数据快很少重用,缓存起来也没有实际意义,und
还会造成物理I/O相当大。 所以这种系统的瓶颈往往是磁盘I/O上面的。
对于OLAP系统,SQL 的优化非常重要,因为它的数据量很大,做全表扫描和索引对性能
上来说差异是非常大的。
其他
Oracle 10g以前的版本建库过程中可供选择的模板有:
Data Warehouse (数据仓库)
General Purpose (通用目的、一般用途)
New Database
Transaction Processing (事务处理)
Oracle 11g的版本建库过程中可供选择的模板有:
一般用途或事务处理
定制数据库
数据仓库
个人对这些模板的理解为:
联机分析处理(OLAP,On-line Analytical Processing),数据量大,DML少。使用数据
仓库模板
联机事务处理(OLTP,On-line Transaction Processing),数据量少,DML频繁,并行
事务处理多,但是一般都很短。使用一般用途或事务处理模板。
决策支持系统(DDS,Decision support system),典型的操作是全表扫描,长查询,长
事务,但是一般事务的个数很少,往往是一个事务独占系统。