12306.cn에서 대규모 웹 사이트의 아키텍처 및 성능 최적화에 대한 심도있는 좋은 기사 토크
12306.cn 웹 사이트가 다운되었습니다,조국 사람들에게 욕을 먹었다。지난 이틀 동안 이것에 대해 생각했습니다.,이 문제를 사용하여 귀하와 웹 사이트의 성능에 대해 대략적으로 논의하고 싶습니다.。서두름 때문에,전적으로 나의 제한된 경험과 이해를 바탕으로,그래서,궁금한 사항이 있으면 함께 토론하고 수정하십시오.。(이것은 또 다른 긴 기사입니다.,성능 문제만 논의,해당 UI에 대해 논의하지 마십시오.,사용자 경험,或是是否把支付和购票下单环节分开的功能性的东西)
业务
任何技术都离不开业务需求,그래서,성능 문제를 설명하기 위해,먼저 비즈니스 문제에 대해 이야기하고 싶습니다.。
- 중 하나,어떤 사람들은 이것을 QQ나 온라인 게임과 비교할 수 있습니다.。하지만 둘은 다른 것 같아요,온라인 게임 및 QQ는 온라인 또는 로그인 시 사용자 자신의 데이터에 더 많이 액세스합니다.,예약 시스템은 센터의 티켓 볼륨 데이터에 액세스합니다.,그것은 다르다。온라인 게임이나 QQ가 될 수 있다고 생각하지 말고 그냥 같다고 생각하세요.。전자 상거래 시스템과 비교할 때 온라인 게임 및 QQ의 백엔드 로드는 여전히 간단합니다.。
- 두번째,어떤 사람들은 춘절 기간에 기차를 예약하는 것이 웹사이트의 플래시 세일과 같다고 말합니다.。정말 비슷하다,그러나 당신의 생각이 표면에 있지 않다면,조금 다르다는 걸 알게 될거야。기차표에 대해,한편으로는 많은 수의 쿼리 작업이 수반됩니다.,게다가 BT는 주문을 할 때 데이터베이스에서 많은 일관된 작업이 필요하다는 것입니다.,한편으로는 시작점에서 끝점까지 각 구간 티켓의 일관성입니다.,반면에,구매자 경로、기차 번호、많은 시간 옵션이 있습니다,주문 방식은 계속 변경됩니다.。그리고 스파이크,그냥 죽여,쿼리 및 일관성 문제가 많지 않음。게다가,세크킬에 대하여,처음 N 사용자의 요청만 수락하도록 만들 수 있습니다(백엔드에서 데이터를 전혀 작동하지 않음)., 사용자의 주문 작업 로그일 뿐입니다.),이런 종류의 사업,메모리 캐시에 죽일 수 있는 시간(초)만 입력하면 됩니다.,데이터 배포도 가능,100상품,10하나의 서버는 10을 넣습니다.,당시에 데이터베이스를 운영할 필요가 없습니다.。주문 수에 충분한 후,스파이크를 중지,그런 다음 배치로 데이터베이스에 쓰기。그리고 초 단위로 판매되는 제품은 많지 않습니다。기차표는 플래시 판매만큼 간단하지 않습니다,봄 축제 여행 시간,거의 모든 티켓이 핫 티켓,그리고 전국에서 온 거의 모든 사람들이,그리고 양도 사업도 있습니다,여러 재고 라인에 트랜잭션 작업이 필요합니다.,생각해봐,이게 얼마나 힘든 일이야。(타오바오의 더블일레븐은 사용자가 300만명에 불과하다.,而火车票瞬时有千万级别甚至是亿级别的)(更新:20141월 11일:타오바오에 접속 후,타오바오의 시스템에 익숙하다,타오바오의 스파이크 활동,본질적으로 사용자는 CDN에 인증 코드를 입력하여 직접 필터링됩니다.,같은:1수천만 명의 사용자가 필터링되고 20,000명의 사용자만 남습니다.,这样数据库就顶得住了)
- 其三,어떤 사람들은 이 시스템을 올림픽 티켓팅 시스템과 비교합니다.。아직은 다른 것 같아요。올림픽 티켓팅 시스템도 온라인화되자마자 폐지됐지만。그러나 올림픽 게임은 복권을 사용합니다.,즉, 선착순 접근 방식이 없습니다.,그리고,그것은 나중에 생각하는 복권입니다,사전에 정보를 받기만 하면 됨,사전에 데이터 일관성을 보장할 필요 없음,자물쇠가 없다,수평으로 확장하기 쉽습니다.。
- 네번째,예약 시스템은 전자 상거래 주문 시스템과 매우 유사해야 합니다.,인벤토리를 수행해야 합니다.:1) 인벤토리를 점유,2) 지불하다(선택사항),3) 재고 운영 차감。일관성 검사가 필요합니다.,즉, 동시성 동안 데이터를 잠글 필요가 있습니다.。B2C 전자 상거래 회사는 기본적으로 이를 비동기적으로 수행합니다.,즉 말하자면,주문이 즉시 처리되지 않습니다,하지만 지연된 처리,성공적으로 처리된 경우에만,시스템에서 주문이 성공했다는 확인 이메일을 보냅니다.。많은 친구들이 실패한 확인 이메일을 받은 것 같습니다.。이것은,데이터 일관성은 동시성에서 병목 현상입니다.。
- 다섯,철도 발권 사업은 음란하다,갑작스런 석방,그리고 일부 투표는 모두가 공유하기에 충분하지 않습니다.,그래서,그래야만 모든 사람이 중국 특성을 가진 비즈니스인 티켓 예매를 할 수 있습니다.。그래서 티켓이 발매되었을 때,수백만 또는 수천만 명의 사람들이 죽임을 당할 것입니다.,조회,주문。수십 분 이내,웹 사이트는 수천만 명의 방문을 받을 수 있습니다.,이것은 무서운 일이다。12306의 피크 방문은 10억 PV라고 합니다.,오전 8시부터 오전 10시까지 집중한다.,정점에서 초당 수천만 PV。
몇 마디 더 말해봐:
- 인벤토리는 B2C의 악몽입니다.,재고 관리는 상당히 복잡합니다.。믿을 수 없어,모든 전통 및 전자 상거래 비즈니스를 요청할 수 있습니다.,재고 관리가 얼마나 어려운지 확인하십시오.。그렇지 않으면,뱅클 인벤토리 물어보는 사람 별로 없을듯。("Jobs Biography"도 읽을 수 있습니다.,Tim이 Apple의 CEO로 취임한 이유를 알 수 있습니다.,最主要的原因是他搞定了苹果的库存周期问题)
- 对于一个网站来说,웹 브라우징의 높은 부하를 쉽게 처리할 수 있습니다.,쿼리 로드를 처리하기 어렵습니다.,그러나 쿼리 결과를 캐싱하여 여전히 수행할 수 있습니다.,가장 어려운 것은 주문의 부담。인벤토리 액세스용,주문을 위해,기본적으로 비동기식으로 수행됩니다.。지난해 더블 11,Taobao의 시간당 주문 수는 약 600,000입니다.,Jingdong은 하루에 400,000만 지원할 수 있습니다(12306보다 더 나쁨).,아마존은 5년 전에 한 시간에 700,000건의 주문을 지원할 수 있었습니다.。보이는,주문하는 것이 우리가 원하는 만큼 성능이 좋지 않습니다.。
- Taobao는 B2C 웹 사이트보다 훨씬 간단합니다.,창고가 없기 때문에,그래서,동일한 제품의 재고를 업데이트하고 쿼리하는 N개의 창고가 있는 B2C와 같은 작업은 없습니다.。주문할 때,B2C 웹사이트에서 창고를 찾아야 합니다.,사용자와 가까운,다시 재고가,이것은 많은 계산이 필요합니다。상상 해봐,당신은 베이징에서 책을 샀습니다.,북경 창고 품절,주변 창고에서 옮겨드립니다.,그런 다음 Shenyang 또는 Xi'an의 창고로 이동하여 재고가 있는지 확인하십시오.,없는 경우,강소 창고를 다시 봐야 한다,기다리다。타오바오는 별로입니다.,각 판매자는 자체 인벤토리를 가지고 있습니다.,재고는 숫자입니다,그리고 인벤토리는 상인들에게 분배됩니다.,오히려 성능 확장에 도움이됩니다.。
- 데이터 일관성은 실제 성능 병목 현상입니다.。어떤 사람들은 nginx가 초당 100,000개의 정적 요청을 처리할 수 있다고 말합니다.,나는 의심하지 않는다。하지만 정적 요청일 뿐입니다.,이론적 가치,대역폭만큼、I/O가 충분히 강함,서버의 컴퓨팅 성능이 충분합니다.,그리고 지원되는 동시 연결 수는 100,000개의 TCP 연결 설정을 견딜 수 있습니다.,그건 문제 없어。그러나 데이터 일관성에 직면하여,이 100,000은 완전히 도달할 수 없는 이론적 가치가 되었습니다.。
나는 너무 많이 말했다,나는 단지 당신에게 사업에서 말하고 싶습니다,우리는 비즈니스 관점에서 봄 축제 철도 티켓 예매 사업의 이상을 진정으로 이해해야 합니다.。
前端性能优化技术
要解决性能的问题,많은 일반적인 방법이 있습니다,아래에 나열합니다,12306은 다음과 같은 기술을 활용하여 질적인 성능 향상을 이루리라 믿습니다.。
하나、前端负载均衡
通过DNS的负载均衡器(一般在路由器上根据路由的负载重定向)可以把用户的访问均匀地分散在多个Web服务器上。이렇게 하면 웹 서버의 요청 부하가 줄어듭니다.。http 요청은 모두 짧은 작업이기 때문에,그래서,이는 매우 간단한 로드 밸런서로 수행할 수 있습니다.。사용자가 가장 가까운 서버에 연결할 수 있도록 CDN 네트워크를 보유하는 것이 가장 좋습니다(CDN에는 일반적으로 분산 저장소가 수반됨).。(关于负载均衡更为详细的说明见“后端的负载均衡”)
두、프런트엔드 링크 수 줄이기
我看了一下12306.cn,打开主页需要建60多个HTTP连接,车票预订页面则有70多个HTTP请求,现在的浏览器都是并发请求的(当然,浏览器的一个页面的并发数是有限的,但是你挡不住用户开多个页面,그리고,后端服务器TCP链接在前端断开始,还不会马上释放或重要)。그래서,只要有100万个用户,就有可能会有6000万个链接(访问第一次后有了浏览器端的cache,这个数会下来,就算只有20%也是百万级的链接数),太多了。一个登录查询页面就好了。把js打成一个文件,把css也打成一个文件,把图标也打成一个文件,用css分块展示。把链接数减到最低。
세、减少网页大小增加带宽
这个世界不是哪个公司都敢做图片服务的,因为图片太耗带宽了。现在宽带时代很难有人能体会到当拨号时代做个图页都不敢用图片的情形(现在在手机端浏览也是这个情形)。我查看了一下12306首页的需要下载的总文件大小大约在900KB左右,如果你访问过了,浏览器会帮你缓存很多,只需下载10K左右的文件。但是我们可以想像一个极端一点的案例,1百万用户同时访问,且都是第一次访问,每人下载量需要1M,如果需要在120秒内返回,那么就需要,1미디엄 * 1미디엄 /120 * 8 = 66Gbps的带宽。很惊人吧。그래서,我估计在当天,12306的阻塞基本上应该是网络带宽,그래서,你可能看到的是没有响应。后面随着浏览器的缓存帮助12306减少很多带宽占用,于是负载一下就到了后端,后端的数据处理瓶颈一下就出来。于是你会看到很多http 500之类的错误。这说明后端服务器垮了。
네、前端页面静态化
静态化一些不常变的页面和数据,并gzip一下。还有一个变态的方法是把这些静态页面放在/dev/shm下,这个目录就是内存,直接从内存中把文件读出来返回,这样可以减少昂贵的磁盘I/O。使用nginx的sendfile功能可以让这些静态文件直接在内核心态交换,可以极大增加性能。
파이브、优化查询
很多人查询都是在查一样的,完全可以用反向代理合并这些并发的相同的查询。这样的技术主要用查询结果缓存来实现,第一次查询走数据库获得数据,并把数据放到缓存,后面的查询统统直接访问高速缓存。为每个查询做Hash,使用NoSQL的技术可以完成这个优化。(这个技术也可以用做静态页面)
对于火车票量的查询,个人觉得不要显示数字,就显示一个“有”或“无”就好了,这样可以大大简化系统复杂度,并提升性能。把查询对数据库的负载分出去,从而让数据库可以更好地为下单的人服务。
육、缓存的问题
缓存可以用来缓存动态页面,也可以用来缓存查询的数据。缓存通常有那么几个问题:
1)缓存的更新。也叫缓存和数据库的同步。有这么几种方法,一是缓存time out,让缓存失效,重查,二是,由后端通知更新,一量后端发生变化,通知前端更新。前者实现起来比较简单,但实时性不高,后者实现起来比较复杂 ,但实时性高。
2)缓存的换页。内存可能不够,그래서,需要把一些不活跃的数据换出内存,这个和操作系统的内存换页和交换内存很相似。FIFO、LRU、LFU都是比较经典的换页算法。相关内容参看Wikipeida的缓存算法。
3)缓存的重建和持久化。缓存在内存,系统总要维护,그래서,缓存就会丢失,如果缓存没了,就需要重建,如果数据量很大,缓存重建的过程会很慢,这会影响生产环境,그래서,缓存的持久化也是需要考虑的。
诸多强大的NoSQL都很好支持了上述三大缓存的问题。
后端性能优化技术
前面讨论了前端性能的优化技术,于是前端可能就不是瓶颈问题了。那么性能问题就会到后端数据上来了。下面说几个后端常见的性能优化技术。
하나、数据冗余
关于数据冗余,즉 말하자면,把我们的数据库的数据冗余处理,也就是减少表连接这样的开销比较大的操作,但这样会牺牲数据的一致性。风险比较大。很多人把NoSQL用做数据,快是快了,因为数据冗余了,但这对数据一致性有大的风险。这需要根据不同的业务进行分析和处理。(注意:用关系型数据库很容易移植到NoSQL上,但是反过来从NoSQL到关系型就难了)
두、数据镜像
几乎所有主流的数据库都支持镜像,也就是replication。数据库的镜像带来的好处就是可以做负载均衡。把一台数据库的负载均分到多台上,同时又保证了数据一致性(Oracle的SCN)。最重要的是,这样还可以有高可用性,一台废了,还有另一台在服务。
数据镜像的数据一致性可能是个复杂的问题,所以我们要在单条数据上进行数据分区,즉 말하자면,把一个畅销商品的库存均分到不同的服务器上,같은,一个畅销商品有1万的库存,我们可以设置10台服务器,每台服务器上有1000个库存,这就好像B2C的仓库一样。
세、数据分区
数据镜像不能解决的一个问题就是数据表里的记录太多,导致数据库操作太慢。그래서,把数据分区。数据分区有很多种做法,一般来说有下面这几种:
1)把数据把某种逻辑来分类。比如火车票的订票系统可以按各铁路局来分,可按各种车型分,可以按始发站分,可以按目的地分……,反正就是把一张表拆成多张有一样的字段但是不同种类的表,이러한,这些表就可以存在不同的机器上以达到分担负载的目的。
2)把数据按字段分,也就是竖着分表。比如把一些不经常改的数据放在一个表里,经常改的数据放在另外多个表里。把一张表变成1对1的关系,이러한,你可以减少表的字段个数,同样可以提升一定的性能。게다가,字段多会造成一条记录的存储会被放到不同的页表里,这对于读写性能都有问题。但这样一来会有很多复杂的控制。
3)平均分表。因为第一种方法是并不一定平均分均,可能某个种类的数据还是很多。그래서,也有采用平均分配的方式,通过主键ID的范围来分表。
4)同一数据分区。这个在上面数据镜像提过。也就是把同一商品的库存值分到不同的服务器上,比如有10000个库存,可以分到10台服务器上,一台上有1000个库存。然后负载均衡。
这三种分区都有好有坏。最常用的还是第一种。数据一旦分区,你就需要有一个或是多个调度来让你的前端程序知道去哪里找数据。把火车票的数据分区,并放在各个省市,会对12306这个系统有非常有意义的质的性能的提高。
네、后端系统负载均衡
前面说了数据分区,数据分区可以在一定程度上减轻负载,但是无法减轻热销商品的负载,对于火车票来说,可以认为是大城市的某些主干线上的车票。这就需要使用数据镜像来减轻负载。使用数据镜像,你必然要使用负载均衡,在后端,我们可能很难使用像路由器上的负载均衡器,因为那是均衡流量的,因为流量并不代表服务器的繁忙程度。따라서,我们需要一个任务分配系统,其还能监控各个服务器的负载情况。
任务分配服务器有一些难点:
- 负载情况比较复杂。什么叫忙?是CPU高?还是磁盘I/O高?还是内存使用高?还是并发高?还是内存换页率高?你可能需要全部都要考虑。这些信息要发送给那个任务分配器上,由任务分配器挑选一台负载最轻的服务器来处理。
- 任务分配服务器上需要对任务队列,不能丢任务啊,所以还需要持久化。并且可以以批量的方式把任务分配给计算服务器。
- 任务分配服务器死了怎么办?这里需要一些如Live-Standby或是failover等高可用性的技术。我们还需要注意那些持久化了的任务的队列如何转移到别的服务器上的问题。
我看到有很多系统都用静态的方式来分配,有的用hash,有的就简单地轮流分析。这些都不够好,一个是不能完美地负载均衡,另一个静态的方法的致命缺陷是,如果有一台计算服务器死机了,或是我们需要加入新的服务器,对于我们的分配器来说,都需要知道的。게다가,还要重算哈希(一致性hash可以部分解决这个问题)。
还有一种方法是使用抢占式的方式进行负载均衡,由下游的计算服务器去任务服务器上拿任务。让这些计算服务器自己决定自己是否要任务。这样的好处是可以简化系统的复杂度,而且还可以任意实时地减少或增加计算服务器。但是唯一不好的就是,如果有一些任务只能在某种服务器上处理,这可能会引入一些复杂度。不过总体来说,这种方法可能是比较好的负载均衡。
파이브、异步、 throttle 和 批量处理
异步、throttle(节流阀) 和批量处理都需要对并发请求数做队列处理的。
- 异步在业务上一般来说就是收集请求,然后延时处理。在技术上就是可以把各个处理程序做成并行的,也就可以水平扩展了。但是异步的技术问题大概有这些,a)被调用方的结果返回,会涉及进程线程间通信的问题。b)如果程序需要回滚,回滚会有点复杂。c)异步通常都会伴随多线程多进程,并发的控制也相对麻烦一些。d)很多异步系统都用消息机制,消息的丢失和乱序也会是比较复杂的问题。
- throttle 技术其实并不提升性能,这个技术主要是防止系统被超过自己不能处理的流量给搞垮了,这其实是个保护机制。使用throttle技术一般来说是对于一些自己无法控制的系统,같은,和你网站对接的银行系统。
- 批量处理的技术,是把一堆基本相同的请求批量处理。같은,大家同时购买同一个商品,没有必要你买一个我就写一次数据库,完全可以收集到一定数量的请求,一次操作。这个技术可以用作很多方面。比如节省网络带宽,我们都知道网络上的MTU(最大传输单元),以态网是1500字节,光纤可以达到4000多个字节,如果你的一个网络包没有放满这个MTU,那就是在浪费网络带宽,因为网卡的驱动程序只有一块一块地读效率才会高。따라서,网络发包时,我们需要收集到足够多的信息后再做网络I/O,这也是一种批量处理的方式。批量处理的敌人是流量低,그래서,批量处理的系统一般都会设置上两个阀值,一个是作业量,另一个是timeout,只要有一个条件满足,就会开始提交处理。
그래서,只要是异步,一般都会有throttle机制,一般都会有队列来排队,有队列,就会有持久化,而系统一般都会使用批量的方式来处理。
云风同学设计的“排队系统” 就是这个技术。这和电子商务的订单系统很相似,就是说,我的系统收到了你的购票下单请求,但是我还没有真正处理,我的系统会跟据我自己的处理能力来throttle住这些大量的请求,并一点一点地处理。一旦处理完成,我就可以发邮件或短信告诉用户你来可以真正购票了。
BGP가 네트워크를 검색하지 않음,我想通过业务和用户需求方面讨论一下云风同学的这个排队系统,因为其从技术上看似解决了这个问题,但是从业务和用户需求上来说可能还是有一些值得我们去深入思考的地方:
1)队列的DoS攻击。가장 먼저,我们思考一下,这个队是个单纯地排队的吗?这样做还不够好,因为这样我们不能杜绝黄牛,而且单纯的ticket_id很容易发生DoS攻击,같은,我发起N个 ticket_id,进入购票流程后,我不买,我就耗你半个小时,很容易我就可以让想买票的人几天都买不到票。有人说,用户应该要用身份证来排队, 这样在购买里就必需要用这个身份证来买,但这也还不能杜绝黄牛排队或是号贩子。因为他们可以注册N个帐号来排队,但就是不买。黄牛这些人这个时候只需要干一个事,把网站搞得正常人不能访问,让用户只能通过他们来买。
2)对列的一致性?对这个队列的操作是不是需要锁?只要有锁,性能一定上不去。상상 해봐,100万个人同时要求你来分配位置号,这个队列将会成为性能瓶颈。你一定没有数据库实现得性能好,그래서,可能比现在还差。抢数据库和抢队列本质上是一样的。
3)队列的等待时间。购票时间半小时够不够?多不多?要是那时用户正好不能上网呢?如果时间短了,用户不够时间操作也会抱怨,如果时间长了,后面在排队的那些人也会抱怨。这个方法可能在实际操作上会有很多问题。게다가,半个小时太长了,这完全不现实,我们用15分钟来举例:有1千万用户,每一个时刻只能放进去1万个,这1万个用户需要15分钟完成所有操作,그래서,这1千万用户全部处理完,需要1000*15m = 250小时,10天半,火车早开了。(我并非信口开河,根据铁道部专家的说明:这几天,平均一天下单100万,그래서,处理1000万的用户需要十天。这个计算可能有点简单了,我只是想说,在这样低负载的系统下用排队可能都不能解决业务问题)
4)队列的分布式。这个排队系统只有一个队列好吗?还不足够好。因为,如果你放进去的可以购票的人如果在买同一个车次的同样的类型的票(比如某动车卧铺),还是等于在抢票,也就是说系统的负载还是会有可能集中到其中某台服务器上。따라서,最好的方法是根据用户的需求——提供出发地和目的地,来对用户进行排队。而这样一来,队列也就可以是多个,只要是多个队列,就可以水平扩展了。这样可以解决性能问题,但是没有解决用户长时间排队的问题。
我觉得完全可以向网上购物学习。在排队(下单)的时候,收集好用户的信息和想要买的票,并允许用户设置购票的优先级,같은,A车次卧铺买 不到就买 B车次的卧铺,如果还买不到就买硬座等等,然后用户把所需的钱先充值好,接下来就是系统完全自动地异步处理订单。成功不成功都发短信或邮件通知用户。이러한,系统不仅可以省去那半个小时的用户交互时间,自动化加快处理,还可以合并相同购票请求的人,进行批处理(减少数据库的操作次数)。这种方法最妙的事是可以知道这些排队用户的需求,不但可以优化用户的队列,把用户分布到不同的队列,还可以像亚马逊的心愿单一样,通过一些计算就可以让铁道部做车次统筹安排和调整(最后,排队系统(下单系统)还是要保存在数据库里的或做持久化,不能只放在内存中,不然机器一down,就等着被骂吧)。
小结
写了那么多,我小结一下:
0)无论你怎么设计,你的系统一定要能容易地水平扩展。즉 말하자면,你的整个数据流中,所有的环节都要能够水平扩展。이러한,当你的系统有性能问题时,“加30倍的服务器”才不会被人讥笑。
1)上述的技术不是一朝一夕能搞定的,没有长期的积累,基本无望。我们可以看到,无论你用哪种都会引发一些复杂性,设计总是在做一种权衡。
2)集中式的卖票很难搞定,使用上述的技术可以让订票系统能有几佰倍的性能提升。동안各个省市建分站,分开卖票,是能让现有系统性能有质的提升的最好方法。
3)春运前夕抢票且票量供远小于求这种业务模式是相当变态的,让几千万甚至上亿的人在某个早晨的8点钟同时登录同时抢票的这种业务模式是变态中的变态。业务形态的变态决定了无论他们怎么办干一定会被骂。
4)为了那么一两个星期而搞那么大的系统,而其它时间都在闲着,有些可惜了,这也就是铁路才干得出来这样的事了。
更新2012年9月27日
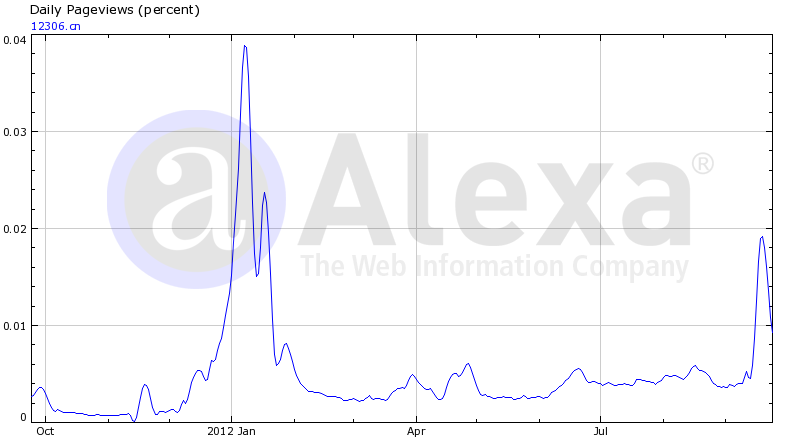
Alexa 统计的12306的PV (注:Alexa的PV定义是:一个用户在一天内对一个页面的多次点击只算一次)
(本文转载时请注明作者和出处,请勿于记商业目的)
转自:http://coolshell.cn/articles/6470.html